이전 포스팅에서는 카프카의 개념, 원리를 알아보았다.
2026.03.01 - [Development/프로젝트] - [Kafka] 카프카의 기본 개념, 원리 (1)
이번 시간에는 직접 구현해보면서, 실제로 어떻게 동작하는지 살펴보도록 하자.
카프카 활용
먼저, 카프카의 활용 방식에 대해 소개하도록 하겠다.
로그, 티켓팅 시스템 등 대용량 트래픽 처리
카프카는 파티션을 통한 수평 확장(Scale-out)이 가능하다.
또한 파티션마다 데이터가 순차적으로 쌓이기 때문에, 대용량 트래픽을 효율적으로 처리할 수 있다.
토픽 별 관심사 분리
카프카에서 이벤트가 발생할 때 비즈니스 로직을 고려해서 토픽을 나누면, 각 서비스의 역할이 분리된다.
만약 주문, 배송, 결제 데이터가 하나의 토픽에 들어가 있으면, 각 서비스가 자신과 관계없는 데이터를 함께 소비하게 된다..
따라서 비즈니스 도메인 별로 토픽을 세분화하면, 독립적으로 로직을 구현하기가 쉬워진다!
이제 코드를 통해 더 자세히 카프카를 알아보자.
(본 예제는 업비트에서 마켓별로 ticker(현재가)를 조회해, 실시간 코인 시세를 보여주는 프로젝트의 일부이다.)
설정
Spring Boot 의존성 추가
implementation 'org.springframework.kafka:spring-kafka'
testImplementation 'org.springframework.kafka:spring-kafka-test'
application.yml
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: coin-price-consumer
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring.json.trusted.packages: "*"
spring.json.value.default.type: com.coinmonitor.dto.CoinPriceMessage
spring.json.use.type.headers: false
listener:
ack-mode: batch- bootstrap-servers: 브로커(서버)에 접근하기 위한 주소
- consumer
- group-id: 컨슈머 그룹 이름
- auto-offset-reset
- earliest: 오프셋 정보가 없을 때 파티션의 처음부터 다시 읽음
- latest: 오프셋 정보가 없을 때 가장 최근에 들어온 메시지부터 읽음
- key-deserializer: 메시지의 key(키)를 String으로 변환
- value-deserializer: 바이트 형태의 데이터를 Java 객체로 역직렬화
- spring.json.trusted.packages: 객체로 변환 가능한 범위
- spring.json.value.default.type: 카프카 컨슈머에서 기본적으로 받는 객체 타입
- spring.json.use.type.headers: 메시지 헤더에 담긴 타입 정보 사용 여부
- true: producer와 consumer가 같은 언어일 때
- false: producer와 consumer가 다른 언어일 때(본인은 producer을 Python, consumer는 Java로 사용하였다!)
- ack-mode: 메시지를 batch 단위로 가져와 처리(throughput 향상)
Producer
다음은 외부에서 가져온 데이터를 카프카 서버(브로커)로 보내는 생산자(producer) 코드이다.
def send_prices(producer, prices):
for item in prices:
market = item.get("market", "")
payload = {
"market": market,
"trade_price": item.get("trade_price"),
"change_rate": item.get("signed_change_rate"),
"acc_trade_volume_24h": item.get("acc_trade_volume_24h"),
"timestamp": item.get("trade_timestamp") or int(time.time() * 1000),
}
try:
producer.send(TOPIC, value=payload, key=market)
except KafkaError as e:
print(f"[ERROR]send failed: {e}")- payload: 카프카 서버로 보낼 레코드의 value
- producer.send(TOPIC, value=payload, key=market)
- TOPIC(coin-prices)에 보낼 데이터를 모아두었다가(batching), 카프카 서버로 비동기 전송
- 이후 flush() 함수를 통해 모든 전송이 마무리될 때까지 대기
전달된 데이터는 카프카 서버의 토픽 내 파티션에 저장된다.
파이썬으로 작성하였지만, 자바 코드로도 충분히~ 구현가능하다.
(자바 producer 예제는 더보기 클릭 ▼)
private final KafkaTemplate<String, Object> kafkaTemplate;
private final RestTemplate restTemplate = new RestTemplate();
...
@Scheduled(fixedRate = 1000)
public void fetchAndSend() {
try {
CoinPriceResponse[] prices = restTemplate.getForObject(UPBIT_URL, CoinPriceResponse[].class); // API 호출
if (prices != null) {
for (CoinPriceResponse price : prices) {
CoinPriceMessage payload = CoinPriceMessage.builder()
.market(price.getMarket())
.trade_price(price.getTrade_price())
.timestamp(price.getTrade_timestamp())
.build();
kafkaTemplate.send(TOPIC, payload.getMarket(), payload);
}
}
} catch (Exception e) {
log.error("error: {}", e.getMessage());
}
}Consumer
다음은 카프카 서버(브로커)에 있는 값들을 가져와(consume) 실시간으로 사용자에게 웹소켓을 통해 전달하는 코드이다.
@KafkaListener(topics = "coin-prices", groupId = "coin-price-consumer")
public void consume(ConsumerRecord<String, CoinPriceMessage> record) {
CoinPriceMessage message = record.value();
if (message == null || message.getMarket() == null) {
return;
}
try {
messagingTemplate.convertAndSend(WS_TOPIC, message);
} catch (Exception e) {
log.error("Failed", e);
}
}
coin-prices 토픽에서 가져온 레코드를 CoinPriceMessage(message) 객체로 저장한 다음,
convertAndSend()를 통해 프론트엔드에 실시간으로 message를 전송한다.
받아온 데이터를 로그에 찍어보면, 다음과 같은 결과를 확인할 수 있다.

컨슈머 그룹 분배 테스트
이전 포스팅에서 컨슈머 그룹 내 컨슈머 수를 적절히 유지하는 것이 성능에 중요하다고 언급했었다.
(컨슈머 수가 적을수록 많은 latency와 부하가 커지고, 많아지면 자원 낭비가 발생한다고 하였음)
이에 컨슈머 수가 늘어날 때, 파티션이 어떻게 분배되는지 확인해보는 간단한 테스트를 진행해 볼 것이다!
먼저 어떤 컨슈머가 어떤 파티션을 차지하는지에 대해 명령어를 통해 확인해보도록 하겠다.
현재 coin-prices 토픽에 존재하는 파티션은 총 3개이다.
1) 컨슈머가 1개일 때

컨슈머 ID 끝자리가 7b4인 한 컨슈머가 세 파티션(0, 1, 2)을 모두 할당하고 있음을 확인할 수 있다.
이때, 파티션 1이 0과 2에 비해 데이터가 2배 존재하는 이유는 키(마켓)가 4개이기 때문이다.
같은 키를 가진 메시지는 항상 같은 파티션으로 가기 때문!

만약, partition1에 있는 한 키의 데이터 양이 지나치게 많다면, 데이터 skew(쏠리는) 현상이 발생할 수 있다.
2) 컨슈머가 2개일 때
기존 컨슈머를 둔 채 새 컨슈머를 실행하고, 컨슈머 그룹의 상태를 확인한 결과는 다음과 같다.
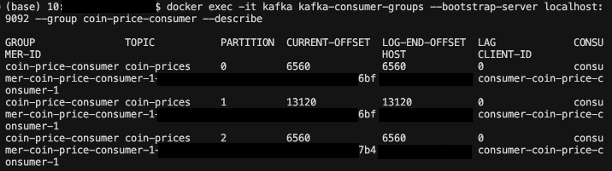
컨슈머 ID 끝자리가 7b4인 한 컨슈머는 기존에 담당했던 파티션 0과 1을 6bf에게 넘겨주고
파티션 2만 담당하게 되었다.
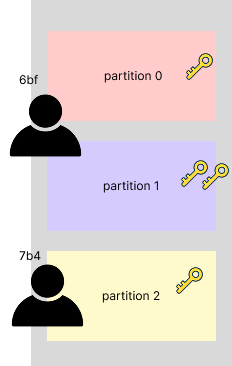
이처럼 카프카는 컨슈머 그룹 내 컨슈머 수에 맞춰 파티션을 유동적으로 재분배한다.
파티션 수에 맞춰 컨슈머를 확장할수록, 데이터는 더 균등하게 분배되어 처리 속도가 빨라질 것이다!
👏
참고
https://techblog.woowahan.com/17386/
'Development > 프로젝트' 카테고리의 다른 글
| [Kafka] 카프카의 기본 개념, 원리 (1) (1) | 2026.03.01 |
|---|